🧮 1.3 Basiskennis AI: Tokens & Context


Je hebt het vast wel eens meegemaakt: je bent in een lang gesprek met een AI-model, bijvoorbeeld om een marketingplan op te stellen. In het begin gaat het fantastisch, maar na een tijdje lijkt het model alles te vergeten wat jullie hebben besproken en begint het met toenemende mate steeds vaker onjuiste voorstellen te doen.

Dit komt doordat de tokens van je gesprek het maximum aantal tokens van het contextvenster beginnen te benaderen. Zie het contextvenster als een werktafel. Alle informatie van jullie gesprek ligt op die tafel. Sommige modellen hebben een grotere tafel dan andere, maar bij elk model is het onvermijdelijk dat de tafel op een gegeven moment vol raakt. Zodra het vol begint te raken gaat het model dingen van de tafel verwijderen om ruimte te maken voor nieuwe informatie. Wat het model weghaalt, is vaak onvoorspelbaar. Het is niet per se de oudste informatie, daarom weet je nooit zeker wat het model 'vergeet'.
📖 Wat zijn Tokens?
AI leest geen woorden zoals wij dat doen. In plaats daarvan splitst het elke tekst op in kleinere stukjes die 'tokens' worden genoemd. Een token kan een heel woord zijn ("appel"), een deel van een woord ("-achtig"), een leesteken (",") of zelfs een spatie. Gemiddeld staat één token voor ongeveer 4 karakters in het Engels, maar dit kan per taal en model verschillen.
De zin "Hallo, hoe gaat het?" kan bijvoorbeeld worden opgedeeld als ["Hall", "o", ",", " hoe", " gaat", " het", "?"]. Elk van deze stukjes telt mee voor de totale hoeveelheid informatie die op de 'werktafel' van het model past.
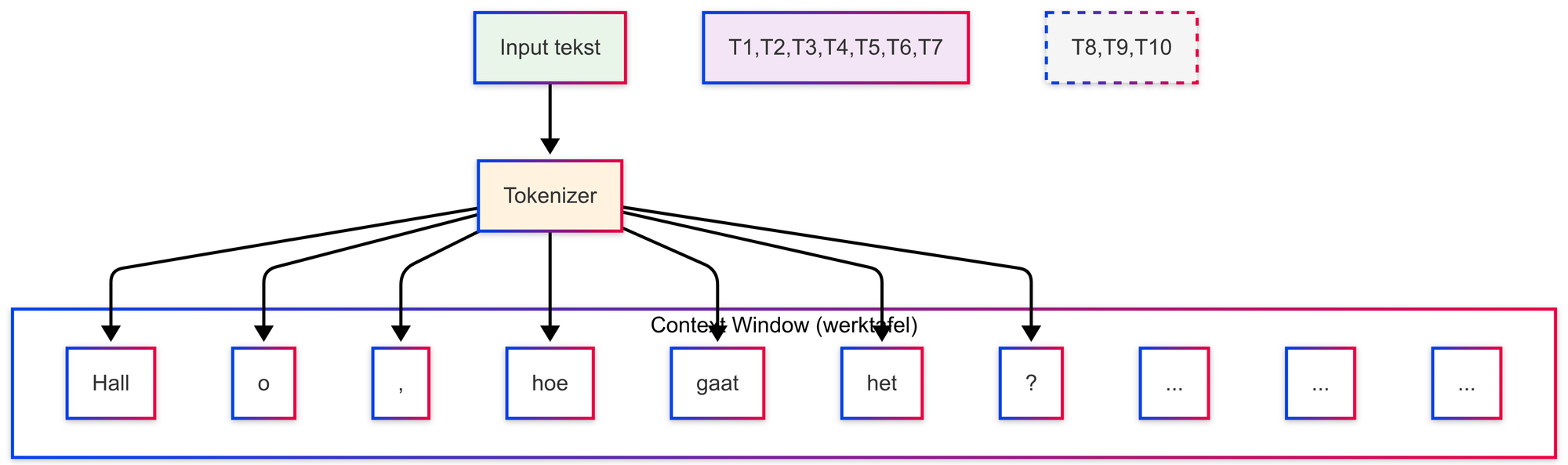
🛠️ Tokenizers
Tokenizers zijn tools die je precies laten zien hoe een AI-model jouw tekst opbreekt in tokens. Ze tellen ook het totale aantal tokens, zodat je een inschatting kunt maken van hoeveel 'ruimte' je prompt inneemt in een bepaald context window.
Om een gevoel te krijgen voor hoe tekst wordt omgezet in tokens, kun je de onderstaande tool van OpenAI eens proberen. Deze laat heel duidelijk per model zien hoe de tokens berekent worden.
https://platform.openai.com/tokenizer
OpenAI Tokenizer 👆
📖 Wat is een Contextvenster?
Elk AI-model heeft dus een specifieke tafelgrootte, ook wel het contextvenster genoemd, dat is uitgedrukt in een maximaal aantal tokens. Het is belangrijk om je bewust te zijn van de maximale contextvensters van elk model, zodat je niet voor verrassingen komt te staan tijdens je promptavontuur. Gezien de snelheid waarmee modellen en hun limieten veranderen is het verstandig om af en toe de onderstaande website te bekijken. Hier kun je alle modellen vergelijken op allerlei verschillende factoren, waaronder de maximale contextvensters.
📖 Een Volle Tafel
Wanneer een gesprek te lang wordt en de werktafel vol raakt, moet het model willekeurig informatie verwijderen. Zoals eerder gezegd, dit is niet altijd de oudste informatie. Het kan een cruciale instructie uit het begin van het gesprek zijn, of een detail uit het midden. De AI 'vergeet' dus letterlijk gedeeltes van het gesprek, omdat er willekeurig notities van de tafel worden gehaald.
Zodra deze cruciale context verdwijnt, raakt het model in de war. Het weet plotseling niet meer wat het oorspronkelijke doel was, welke eisen je had gesteld, of welke eerdere beslissingen zijn genomen. Het probeert dan te antwoorden op basis van de informatie die nog beschikbaar is, wat leidt tot onsamenhangende of "rare" resultaten die je misschien herkent.
Hieronder staan een aantal effectieve strategieën om hier bewust mee om te gaan:
- Splits Grote Taken Op: Wees je bewust van de limieten tijdens het plannen. Als je een grote, complexe taak hebt, splits deze dan op in kleinere, beheersbare subtaken die elk afzonderlijk binnen het context window kunnen worden opgelost. Als je het moeilijk vind om dit te bepalen kan je natuurlijk ook AI gebruiken:
"Ik wil [groot doel beschrijven]. Gezien de complexiteit wil ik dit opdelen in kleinere stappen om te voorkomen dat we de context verliezen. Maak een logisch, stapsgewijs plan van aanpak om dit doel te bereiken. Elke stap moet een duidelijke, afgebakende taak zijn.". - Context Engineering: Denk goed na over welke informatie relevant is voor het uitvoeren van je taak en zorg ervoor dat deze informatie aan het begin duidelijk is. Voeg echter geen irrelevante informatie toe aan de prompt of context, dit bespaart tokens en voorkomt verwarring.
- Herhaal Belangrijke Info & Neem de Leiding: Pas je mindset aan. Verwacht niet dat een AI alles onthoudt. Als je weet dat bepaalde informatie cruciaal is voor de volgende stap, herhaal die informatie dan gewoon, ook al heb je het eerder al gezegd. Stap af van de hoop dat de AI alles in 1 keer goed doet en neem zelf het heft in handen door de belangrijkste context continu vooraan op de werktafel te leggen, ookal denk je dat de AI het misschien wel zal snappen.
❌ Worst Case Prompterio
Als je merkt dat je ruimte tekort komt, laten de meeste apps en modellen je dat tegenwoordig wel op tijd weten. Als dit gebeurt, of als je merkt dat het gesprek niet zo soepel verloopt als in het begin, kun je de agent ook zelf vragen om het gesprek samen te vatten met alle belangrijke punten zodat de volgende agent precies weet waar het verder moet gaan. Zie hieronder een zeer effectief voorbeeldprompt van Claude Code.
Your task is to create a detailed summary of the conversation so far, paying close attention to the user's explicit requests and your previous actions.
This summary should be thorough in capturing technical details, code patterns, and architectural decisions that would be essential for continuing development work without losing context.
Before providing your final summary, wrap your analysis in <analysis> tags to organize your thoughts and ensure you've covered all necessary points. In your analysis process:
1. Chronologically analyze each message and section of the conversation. For each section thoroughly identify:
- The user's explicit requests and intents
- Your approach to addressing the user's requests
- Key decisions, technical concepts and code patterns
- Specific details like file names, full code snippets, function signatures, file edits, etc
2. Double-check for technical accuracy and completeness, addressing each required element thoroughly.
Your summary should include the following sections:
1. Primary Request and Intent: Capture all of the user's explicit requests and intents in detail
2. Key Technical Concepts: List all important technical concepts, technologies, and frameworks discussed.
3. Files and Code Sections: Enumerate specific files and code sections examined, modified, or created. Pay special attention to the most recent messages and include full code snippets where applicable and include a summary of why this file read or edit is important.
4. Problem Solving: Document problems solved and any ongoing troubleshooting efforts.
5. Pending Tasks: Outline any pending tasks that you have explicitly been asked to work on.
6. Current Work: Describe in detail precisely what was being worked on immediately before this summary request, paying special attention to the most recent messages from both user and assistant. Include file names and code snippets where applicable.
7. Optional Next Step: List the next step that you will take that is related to the most recent work you were doing. IMPORTANT: ensure that this step is DIRECTLY in line with the user's explicit requests, and the task you were working on immediately before this summary request. If your last task was concluded, then only list next steps if they are explicitly in line with the users request. Do not start on tangential requests without confirming with the user first.
If there is a next step, include direct quotes from the most recent conversation showing exactly what task you were working on and where you left off. This should be verbatim to ensure there's no drift in task interpretation.
Here's an example of how your output should be structured:
<example>
<analysis>
[Your thought process, ensuring all points are covered thoroughly and accurately]
</analysis>
<summary>
1. Primary Request and Intent:
[Detailed description]
2. Key Technical Concepts:
- [Concept 1]
- [Concept 2]
- [...]
3. Files and Code Sections:
- [File Name 1]
- [Summary of why this file is important]
- [Summary of the changes made to this file, if any]
- [Important Code Snippet]
- [File Name 2]
- [Important Code Snippet]
- [...]
4. Problem Solving:
[Description of solved problems and ongoing troubleshooting]
5. Pending Tasks:
- [Task 1]
- [Task 2]
- [...]
6. Current Work:
[Precise description of current work]
7. Optional Next Step:
[Optional Next step to take]
</summary>
</example>
Please provide your summary based on the conversation so far, following this structure and ensuring precision and thoroughness in your response.
There may be additional summarization instructions provided in the included context. If so, remember to follow these instructions when creating the above summary. Examples of instructions include:
<example>
## Compact Instructions
When summarizing the conversation focus on typescript code changes and also remember the mistakes you made and how you fixed them.
</example>
<example>
# Summary instructions
When you are using compact - please focus on test output and code changes. Include file reads verbatim.
</example>
Wekelijks gratis nieuwe lessen, prompts en relevante updates rechtstreeks in je mailbox.






Ledendiscussie